Keynote - Why is Replace Fonts greyed out?
Very short & sweet this post, but Google turned up nothing when I was stuck so hopefully I’ll save someone else some head scratching by sharing this.
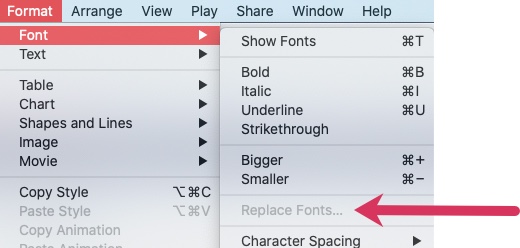
Very short & sweet this post, but Google turned up nothing when I was stuck so hopefully I’ll save someone else some head scratching by sharing this.
As you may already realise, Kafka is not just a fancy message bus, or a pipe for big data. It’s an event streaming platform! If this is news to you, I’ll wait here whilst you read this or watch this…
Streaming data from Kafka to Elasticsearch is easy with Kafka Connect - you can see how in this tutorial and video.
One of the things that sometimes causes issues though is how to get location data correctly indexed into Elasticsearch as geo_point fields to enable all that lovely location analysis. Unlike data types like dates and numerics, Elasticsearch’s Dynamic Field Mapping won’t automagically pick up geo_point data, and so you have to do two things:
STRUCT)There was a good question on StackOverflow recently in which someone was struggling to find the appropriate ksqlDB DDL to model a source topic in which there was a variable number of fields in a STRUCT.
Let’s imagine we have XML data on a queue in IBM MQ, and we want to ingest it into Kafka to then use downstream, perhaps in an application or maybe to stream to a NoSQL store like MongoDB.
We saw in the first post how to hack together an ingestion pipeline for XML into Kafka using a source such as curl piped through xq to wrangle the XML and stream it into Kafka using kafkacat, optionally using ksqlDB to apply and register a schema for it.
The second one showed the use of any Kafka Connect source connector plus the kafka-connect-transform-xml Single Message Transformation. Now we’re going to take a look at a source connector from the community that can also be used to ingest XML data into Kafka.
We previously looked at the background to getting XML into Kafka, and potentially how [not] to do it. Now let’s look at the proper way to build a streaming ingestion pipeline for XML into Kafka, using Kafka Connect.
If you’re unfamiliar with Kafka Connect, check out this quick intro to Kafka Connect here. Kafka Connect’s excellent plugable architecture means that we can pair any source connector to read XML from wherever we have it (for example, a flat file, or a MQ, or anywhere else), with a Single Message Transform to transform the XML into a payload with a schema, and finally a converter to serialise the data in a form that we would like to use such as Avro or Protobuf.
What would a blog post on rmoff.net be if it didn’t include the dirty hack option? 😁
The secret to dirty hacks is that they are often rather effective and when needs must, they can suffice. If you’re prototyping and need to JFDI, a dirty hack is just fine. If you’re looking for code to run in Production, then a dirty hack probably is not fine.
abcde - Error trying to calculate disc ids without lead-out informationShort & sweet to help out future Googlers. Trying to use abcde I got the error:
[WARNING] something went wrong while querying the CD... Maybe a DATA CD or the CD is not loaded?
[WARNING] Error trying to calculate disc ids without lead-out information.Running IBM MQ in a Docker container and the client connecting to it was throwing repeated Channel was blocked errors.
One of my favourite hacks for getting data into Kafka is using kafkacat and stdin, often from jq. You can see this in action with Wi-Fi data, IoT data, and data from a REST endpoint. This is fine for getting values into a Kafka message - but Kafka messages are key/value, and being able to specify a key is can often be important.
Here’s a way to do that, using a separator and some jq magic. Note that at the moment kafkacat only supports single byte separator characters, so you need to choose carefully. If you pick a separator that also appears in your data, it’s possibly going to have unintended consequences.
Readers of a certain age and RDBMS background will probably remember northwind, or HR, or OE databases - or quite possibly not just remember them but still be using them. Hardcoded sample data is fine, and it’s great for repeatable tutorials and examples - but it’s boring as heck if you want to build an example with something that isn’t using the same data set for the 100th time.
Here’s a collection of Kafka-related talks, just for you.
Each one has 🍿🎥 a recording, 📔 slides, and 👾 code to go and try out.
Kafka Connect is the integration API for Apache Kafka. Check out this video for an overview of what Kafka Connect enables you to do, and how to do it.
There’s ways, and then there’s ways, to count the number of records/events/messages in a Kafka topic. Most of them are potentially inaccurate, or inefficient, or both. Here’s one that falls into the potentially inefficient category, using kafkacat to read all the messages and pipe to wc which with the -l will tell you how many lines there are, and since each message is a line, how many messages you have in the Kafka topic:
$ kafkacat -b broker:29092 -t mytestopic -C -e -q| wc -l
3Google Chrome automagically adds sites that you visit which support searching to a list of custom search engines. For each one you can set a keyword which activates it, so based on the above list if I want to search Amazon I can just type a <tab> and then my search term

I had the pleasure of presenting at DataEngBytes recently, and am delighted to share with you the 🗒️ slides, 👾 code, and 🎥 recording of my ✨brand new talk✨:
