In my quest to bring myself up to date with where the data & analytics engineering world is at nowadays, I’m going to build on my exploration of the storage and access technologies and look at the tools we use for loading and transforming data.
The approach that many people use now is one of EL-T. That is, get the [raw] data in, and then transform it. I wrote about this in more detail elsewhere including the difference between ETL and ELT, and the difference between ELT now and in the past. In this article I’m going to look more at the tools themselves. That said, it’s worth recapping why the shift has come about. From my perspective it’s driven by a few things.
-
One is the technology. It’s cheaper to store more data when storage is decoupled from compute (HDFS, S3, etc). It’s also possible to process bigger volumes of data, with the prevalence of distributed systems (such as Apache Spark) whether on-premises or the ubiquitous Cloud datawarehouses (BigQuery, Snowflake, et al).
The result of it being cheaper, and possible, to handle larger volumes of data means that we don’t have to over-optimise the front of the pipeline. In the past we had to transform the data before loading simply to keep it at a manageable size.
Working with the raw data has lots of benefits, since at the point of ingest you don’t know all of the possible uses for the data. If you rationalise that data down to just the set of fields and/or aggregate it up to fit just a specific use case then you lose the fidelity of the data that could be useful elsewhere. This is one of the premises and benefits of a data lake done well.
Of course, despite what the "data is the new oil" vendors told you back in the day, you can’t just chuck raw data in and assume that magic will happen on it, but that’s a rant for another day ;-)
-
The second shift—which is quite possibly related to the one above—that I see is the broadening of scope in teams and roles that are involved in handling data. If you only have a single central data team they can require and enforce tight control of the data and the processing. This has changed in recent years and now it’s much more likely you’ll have multiple teams working with data, perhaps one sourcing the raw data, and another (or several others) processing it. That processing isn’t just aggregating it for a weekly printout for the board meeting, but quite possibly for multiple different analytical uses across teams, as well as fun stuff like Reverse ETL and training ML models.
So what are the kind of tools we’re talking about here, and what are they like to use?
Transformation - dbt 🔗
Let’s cut to the chase on this one because it’s the easiest. Once your data is loaded (and we’ll get to how we load it after this), the transformation work that is done on it will quite likely be done by dbt. And if it’s not, you’ll invariably encounter dbt on your journey of tool selection.

Everywhere I look, it’s dbt. People writing about data & analytics engineering are using dbt. Companies in the space with products to sell are cosying up to dbt and jumping on their bandwagon. It’s possible it could fail…but not for now.
It took me a while to grok where dbt comes in the stack but now that I (think) I have it, it makes a lot of sense. I can also see why, with my background, I had trouble doing so. Just as Apache Kafka isn’t easily explained as simply another database, another message queue, etc, dbt isn’t just another Informatica, another Oracle Data Integrator. It’s not about ETL or ELT - it’s about T alone. With that understood, things slot into place. This isn’t just my take on it either - dbt themselves call it out on their blog:
dbt is the T in ELT
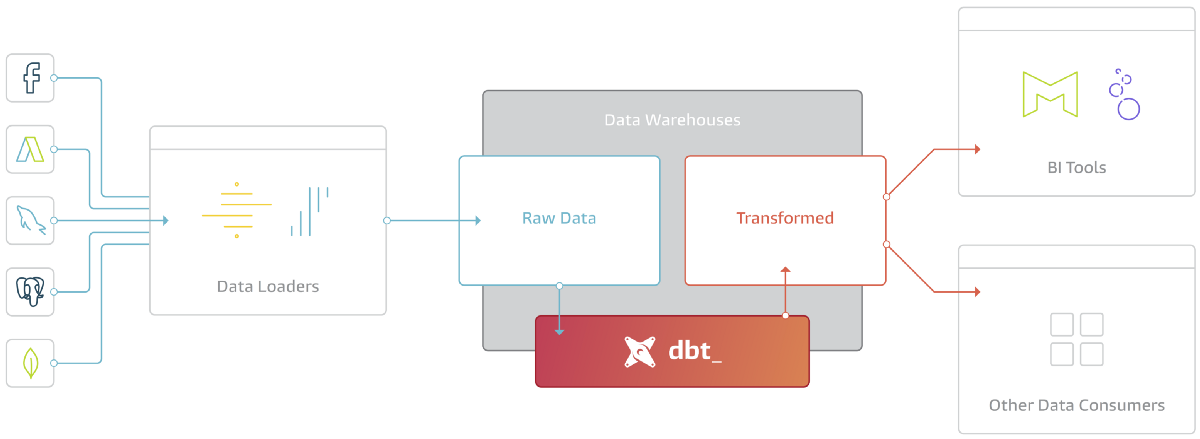
What dbt does is use SQL with templating (and recently added support for Python) to express data transformations, build dependency graphs between those, and executes them. It does a bunch of things around this including testing, incremental loading, documentation, handling environments, and so on—but at its heart that’s all its doing. This raw table of website clicks here, let’s rename these fields, un-nest this one, mask that one, and aggregate that other one. Use the result of that to join to order data to produce a unified view of website/order metrics.
Here’s a simple example:
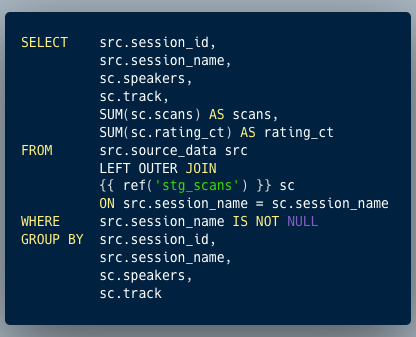
In this the only difference from straight-up regular SQL is {{ ref('stg_scans') }} which refers to another SQL definition (known as a 'model'), and which gives dbt the smarts to know to build that one before this.
A more complex example looks like this:
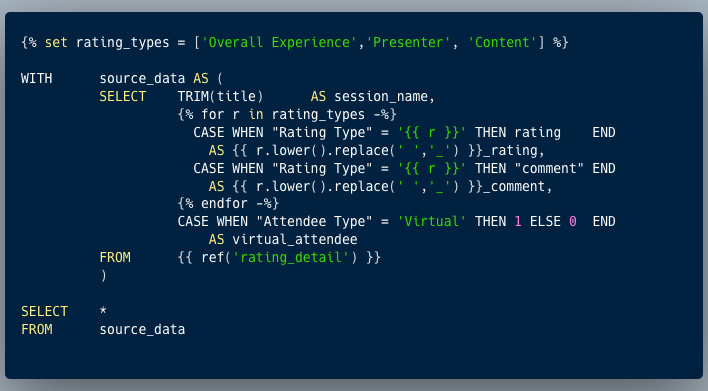
Here we’ve got some Jinja (which technically the ref() is above but let’s not nit-pick) to iterate over three different values of an entity (rating_type) in order to generate some denormalised SQL.
That, in a nutshell, is what dbt does. You can read more about my experiments with it as well as check out their super-friendly and helpful community.
So we’ve figured out Transformation…what about Extract and Load? 🔗
Whilst dbt seems to be dominant in the Transform space, the ingest of data prior to transformation (a.k.a. "Extract & Load") is offered by numerous providers. Almost all are "no-code" or "low-code", and an interesting shift from times of yore is that the sources from which data is extracted is often not an in-house RDBMS but a SaaS provider - less Oracle EBS in your local data center and more Salesforce in the Cloud.
Fivetran is an established name here, along with many others including Stitch (now owned by Talend), Airbyte, Azure Data Factory, Segment, Matillion, and more. Many of these also offer some light transformation of data along the way (such as masking or dropping sensitive fields, or massaging the schema of the data).
Checking out Fivetran and Airbyte 🔗
I’ve taken a look at a couple of SaaS E/L providers side-by-side to understand what they do, what it’s like to use them, and any particular differences. I picked Fivetran and Airbyte, the former because it’s so commonly mentioned, the latter because they were at Current 2022 and had nice swag :D
Airbyte offer a comparison between themselves and Fivetran - taken with a pinch of salt it’s probably a useful starting point if you want to get into the differences between them. Airbyte is open-source and available to run yourself, and also as a cloud service (which is what I’m going to use).
Signup 🔗
Both services offer a 14-day free trial, with fairly painless signup forms
Fivetran wants more data from me and makes me validate my email before letting me in whilst Airbyte wants to validate my email but lets me straight into the dashboard which is nice. Fivetran also sends annoying SDR nurture emails after signup which Airbyte doesn’t.
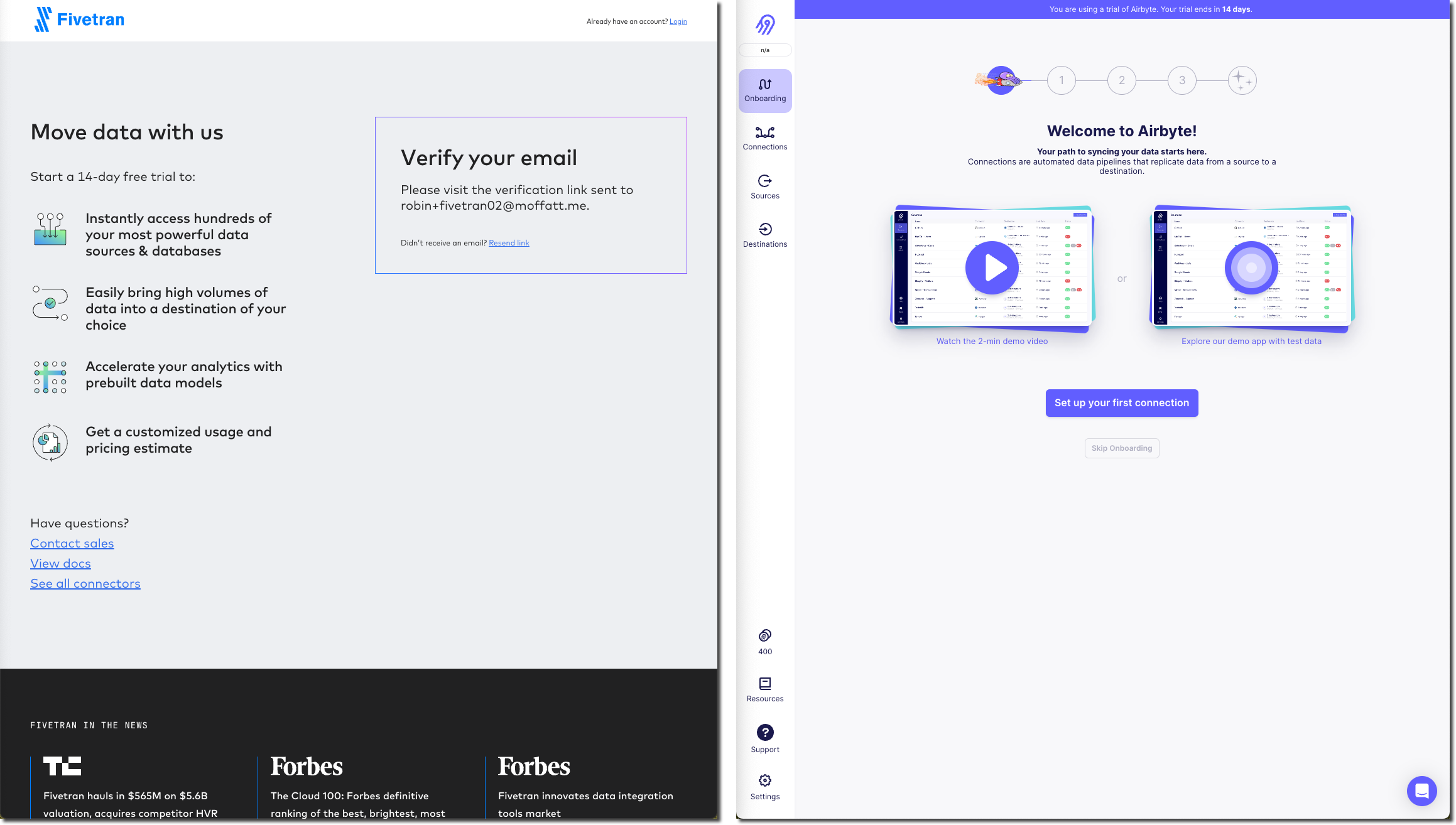
Getting started 🔗
The first screen that I land on after signup for Airbyte feels nicer - a big "Set up your first connection" button, which resonates more than Fivetran’s "Add destination". For me that’s back-to-front since I want to tell it where to get data from and then I’ll explain where to put it. But perhaps that’s just me.
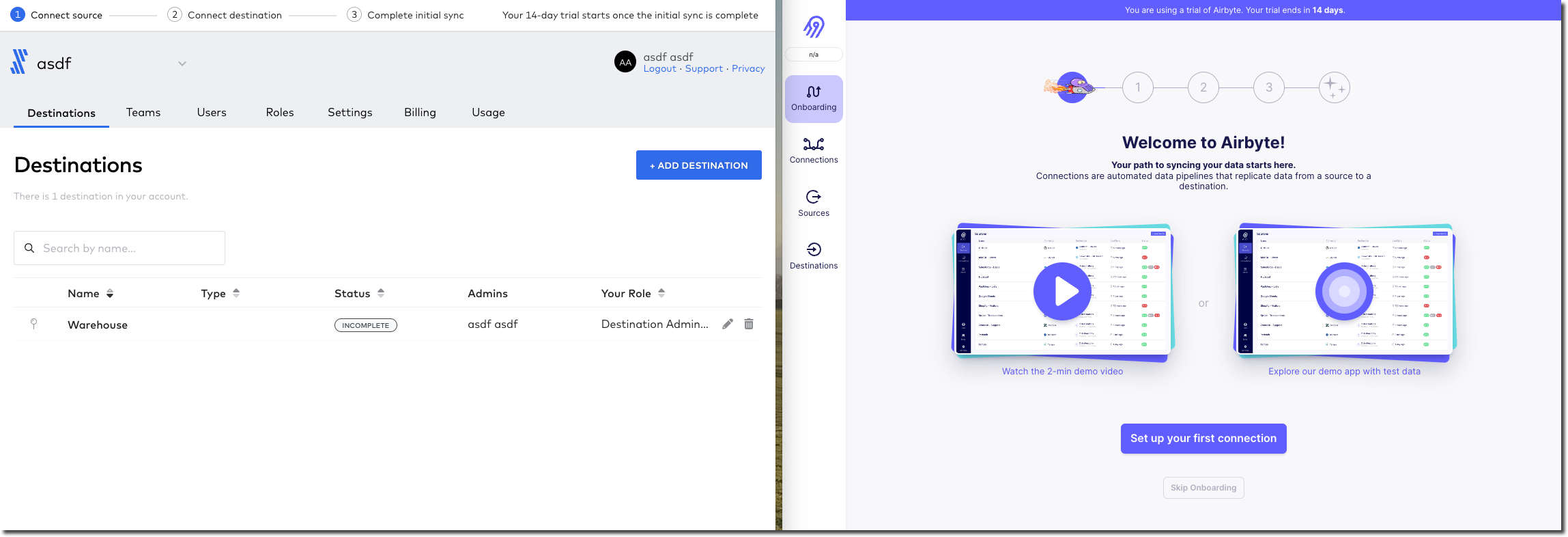
For both services I’m going to use GitHub as a source, and BigQuery as my target, with the theoretical idea of creating an analysis of my blog updates (it’s hosted on GitHub). To this I could add in the future other data sources such as Google Analytics.
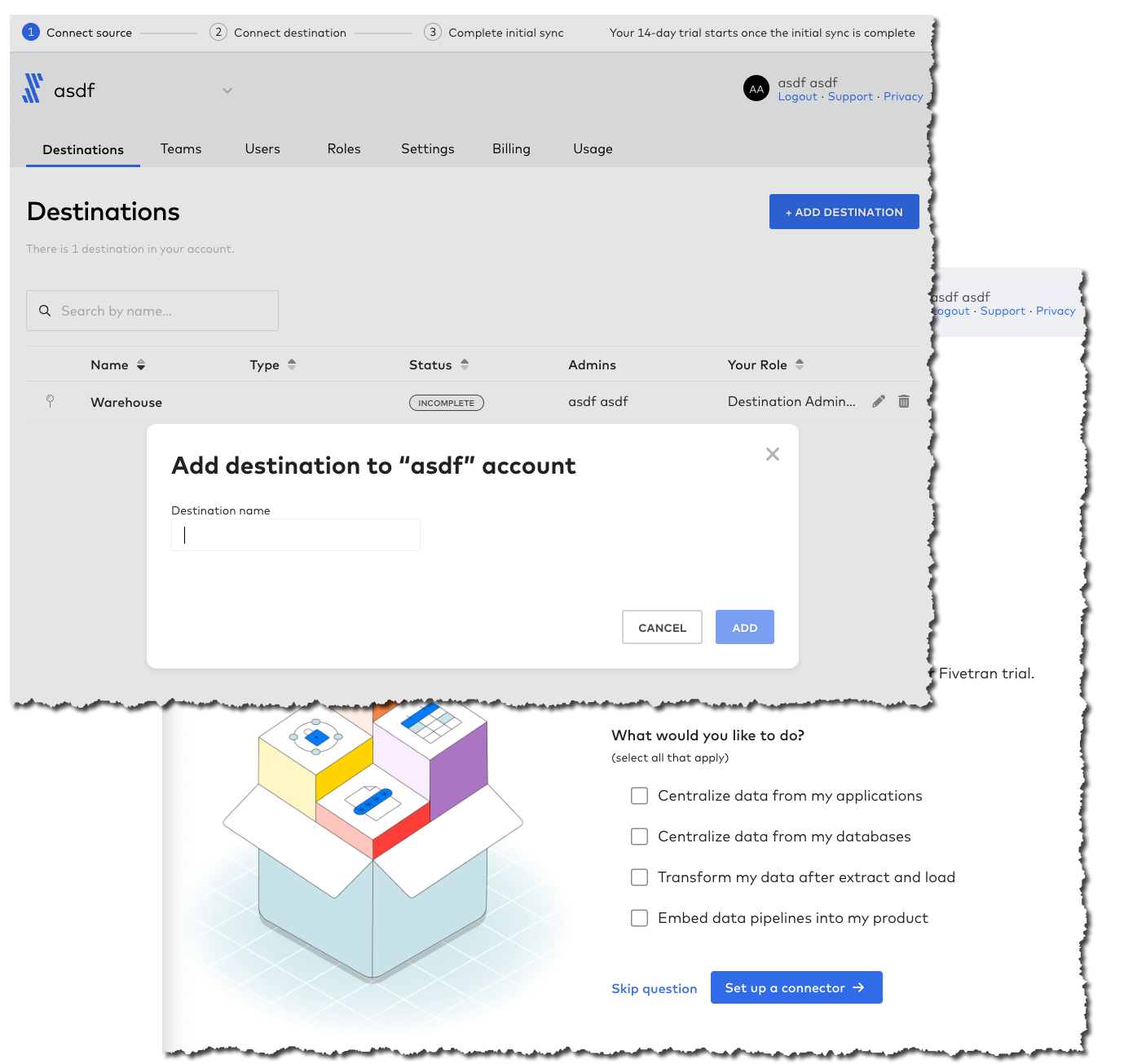
I click the big "Add destination" button in Fivetran and get asked what destination I want to create. This is a bit confusing, and I can see listed already one destination called "Warehouse". I cancel that dialog, and click on the "Edit" button next to the existing destination. This just renames it, so I cancel that. Third time lucky—I click on the "Warehouse" destination name itself and now I’ve launched a 🧙🪄wizard! I click "Skip question".
Selecting the source 🔗
Several clicks in Fivetran and some confusion later, I’ve caught up with where Airbyte was after the single obvious "Set up your first connection" click - selecting my source.
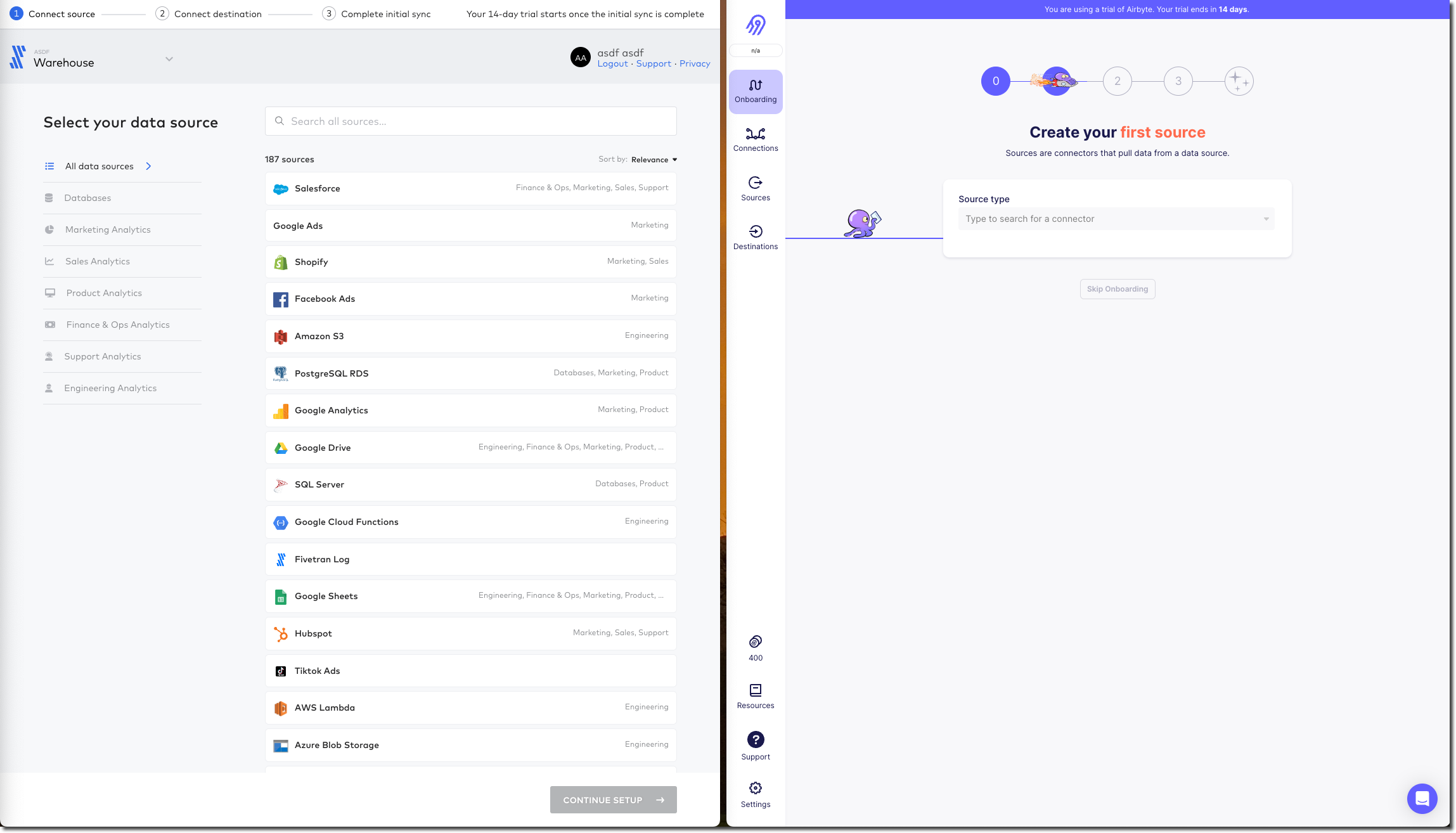
Airbyte lists the connectors alphabetically, and you can also search. Fivetran lists its connectors…randomly?? and its search seem to return odd partial match results
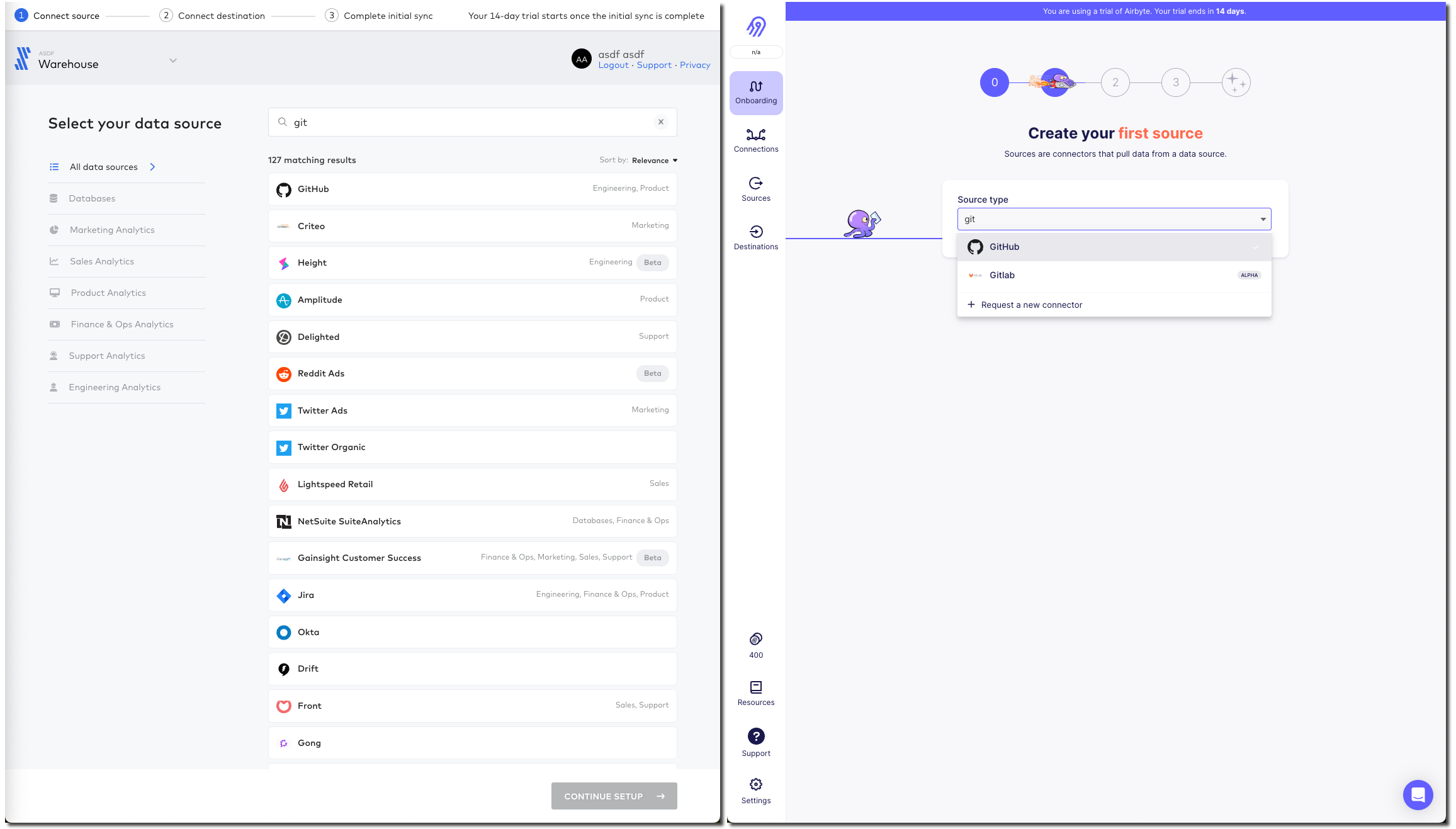
Configuring the source 🔗
With the GitHub connector selected on both, I can now configure it. Both have a nice easy "Authenticate" button which triggers the authentication with my GitHub account. Once done I can select for which repository I want to pull data. Airbyte lets me type it freeform (which is faster but error-prone and relies on me knowing the exact name and owner), whilst Fivetran insists that I only pick from an available list that it has to fetch (mildly annoying if you know the exact name already)
Airbyte slightly annoyingly insists that I enter a "Start date" which I would definitely want the option to do but not mandatory. By default I’d assume I want all data (which is presumably the assumption that Fivetran made because I didn’t have to enter it). I have to freeform enter an ISO timestamp, for which the tooltip helpfully shows the format but is still an extra step nonetheless.
Both connectors run a connection test after the configuration is complete
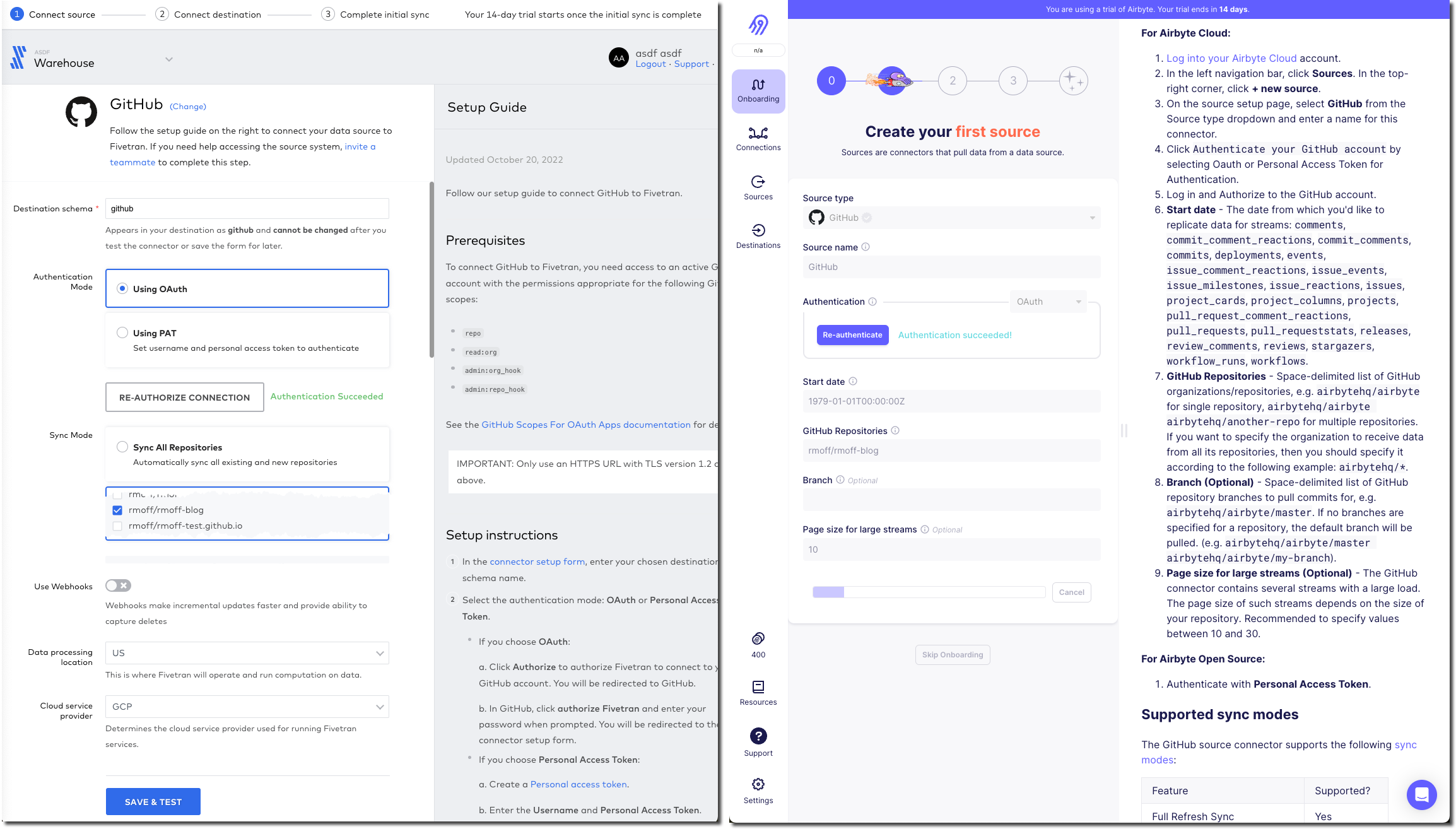
Configuring the target 🔗
Now we specify the target for the data. The BigQuery connector is easy to find on the list of destinations that each provide. As a side note, one thing I’ve noticed with the Fivetran UI is that it’s the more old-school "select, click next, select, click next" vs Airbyte’s which tends to just move on between screens once you select the option.
For my BigQuery account I’ve created and exported a private key for a service account (under IAM & Admin → Service Accounts, then select the service account and Keys tab, and Create new key). Both Fivetran and Airbyte just have a password field into which to paste the multi-line JSON. It seems odd but it works.
Other than the authentication key, Fivetran just needs the Project ID and it’s ready to go. Airbyte also needs a default Dataset location and ID. On the click-click-click done stakes, Fivetran is simpler in this respect (few options that have to be set).
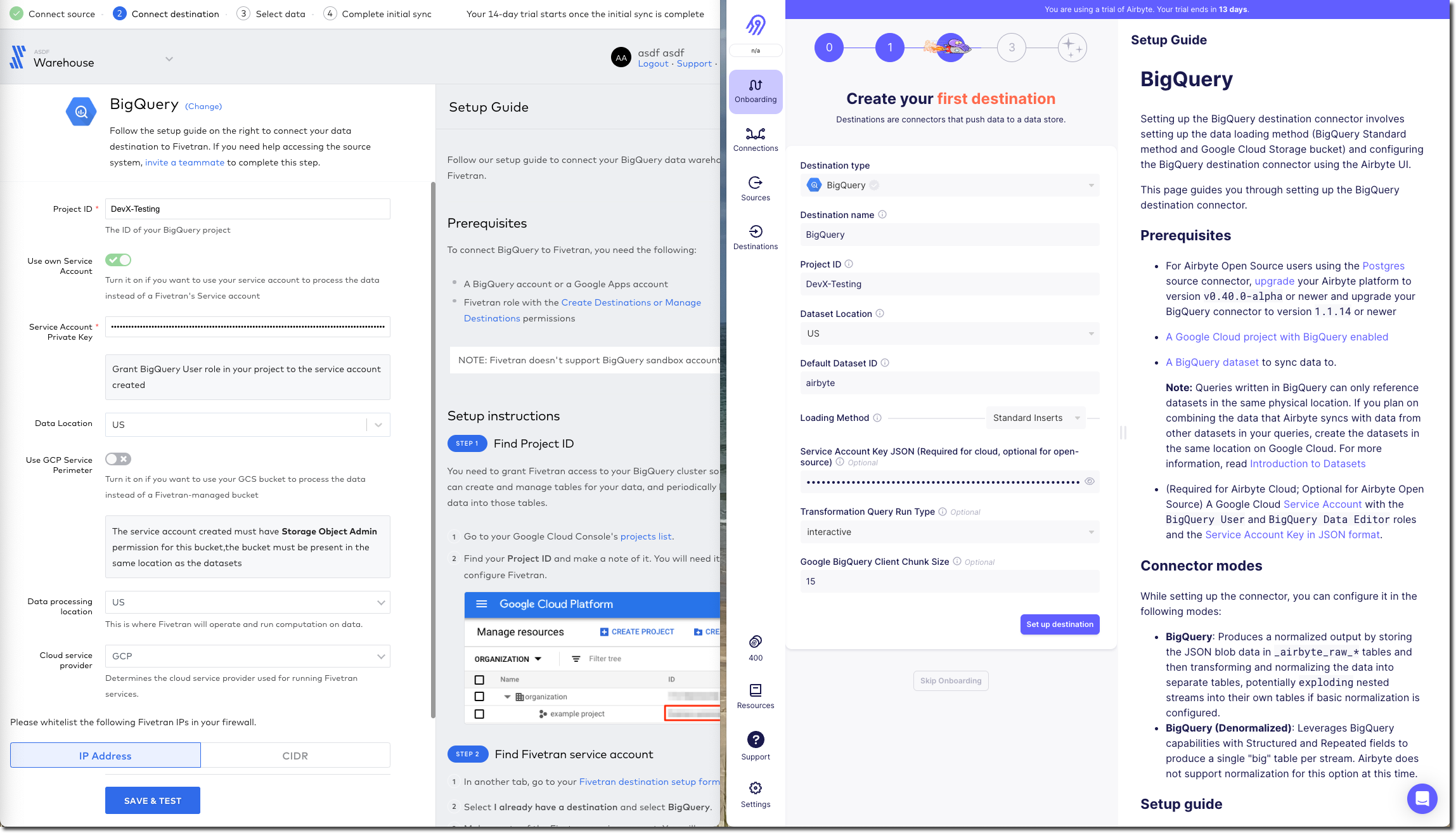
Configuring the extract 🔗
Once the connection has been validated, Fivetran and Airbyte move on to what data is to be synced, and how. The screens diverge a bit here so I’ll discuss them one at a time.
Fivetran keeps things simple with an option to just Sync all data (default), or Choose columns to block or hash. If I select the latter than Fivetran goes off the get the schema and then somewhat jarringly does a "don’t call us, we’ll call you" screen, promising to email me when things are ready…
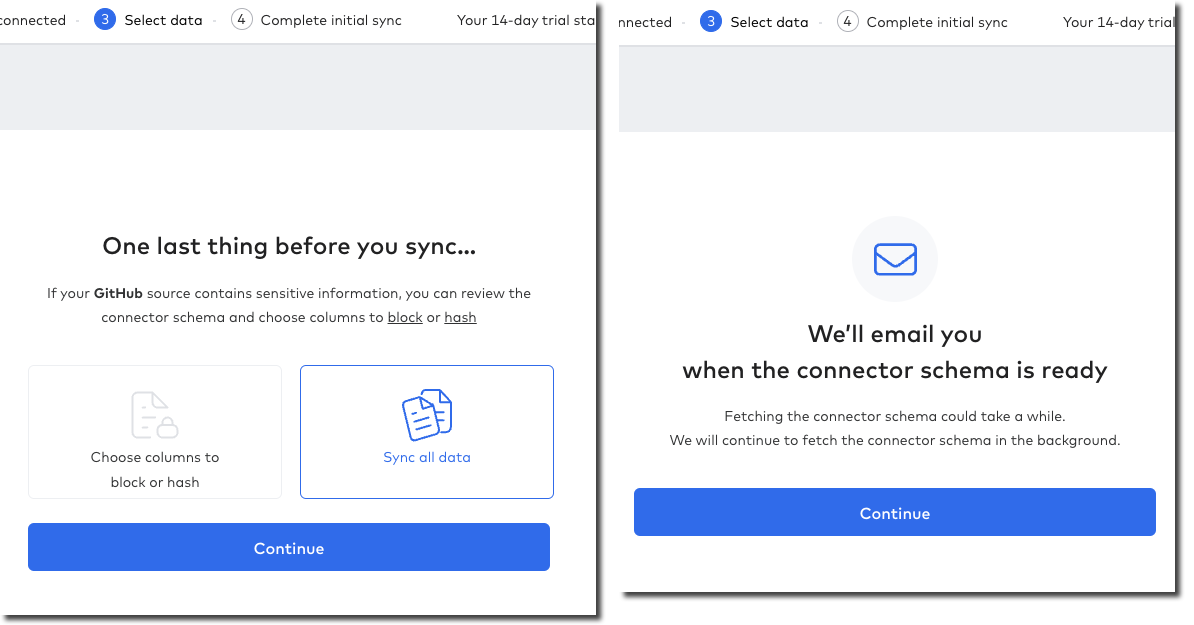
…after which Continue dumps you on a dashboard from which it’s kinda unclear what I do now. Did I create my connector? Is it syncing everything (there’s a spinning action icon next to Status so perhaps?).
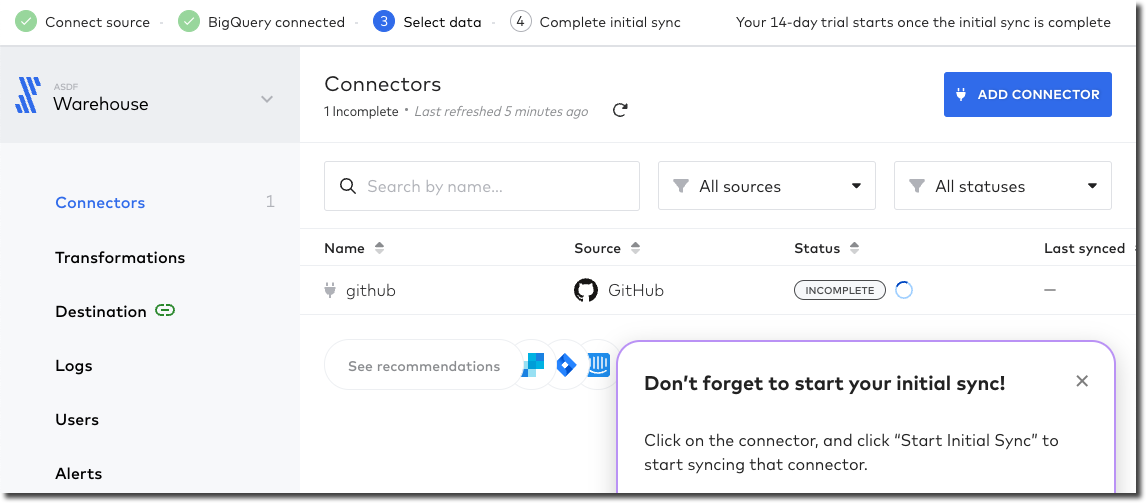
Clicking on the pipeline provides the clarity that was missing previously:
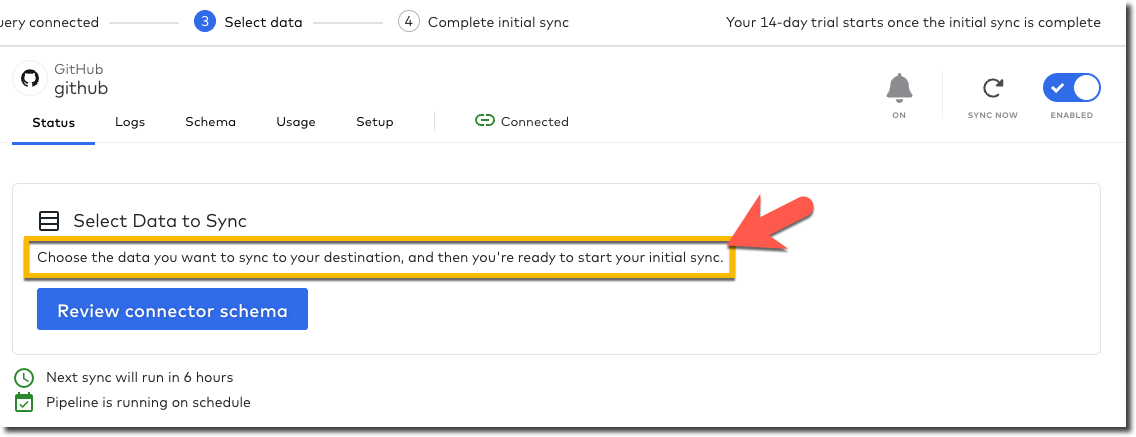
Whilst I sit tight, barely able to control my anticipation at getting the promised email from Fivetran about the schema, I head over to Airbyte. The last thing I did here was confirm my BigQuery connection details, which were successfully tested. If we remember what Fivetran did—a simple screen with two simple buttons "Let’s go" or "Let’s mask some fields", Airbyte’s is somewhat different. You could say bewildering; you could say powerful - 🍅tomato/🍅tomato, 🥔potato/🥔potato.
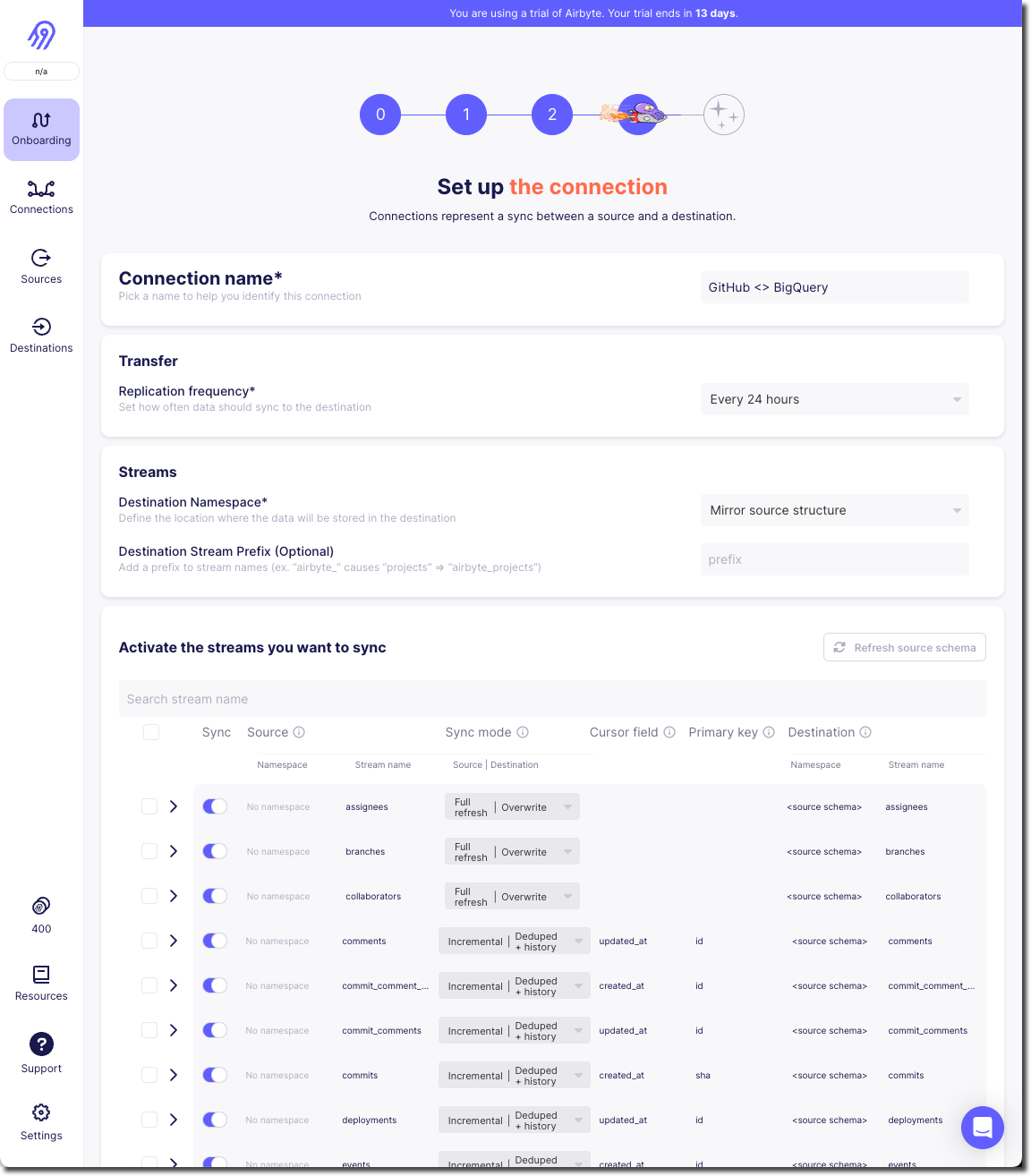
It starts off simple - how often do we want to sync, what do we call it. Then what is our Destination Namespace? Here’s the abstraction coming through, because as a bit of a n00b to all this I’d rather it be asking with the specific term relevant to my destination. What Dataset do I want to write to in BigQuery? But OK, we’ve wrapped our heads around that. But now… now…
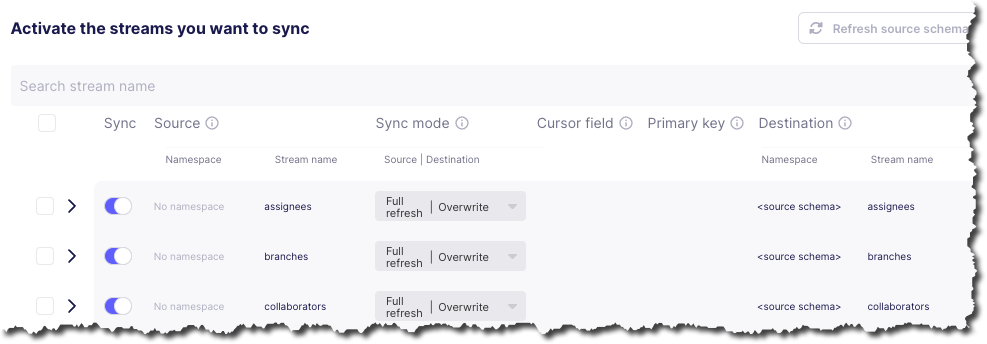
My two big issues with this are:
-
I’m thrown in hard and deep to the world of Sync mode, Cursor field, and more. These things exist, and are important, but I’m just a humble n00b trying to find my way in the world. Do I need to know this stuff now? If Fivetran can abstract it, hide it, or set some suitable defaults, why can’t Airbyte? Sure, give me an "advanced options" button to display this, but I’m pretty daunted now. This brings me to my next issue:
-
The user interface (UI) is not clear.
-
First, do I need to change any of these options, or can I just proceed? If I scroll all the way down there’s actually a
Set up connectionbutton that’s not greyed out, so perhaps I can just click on that?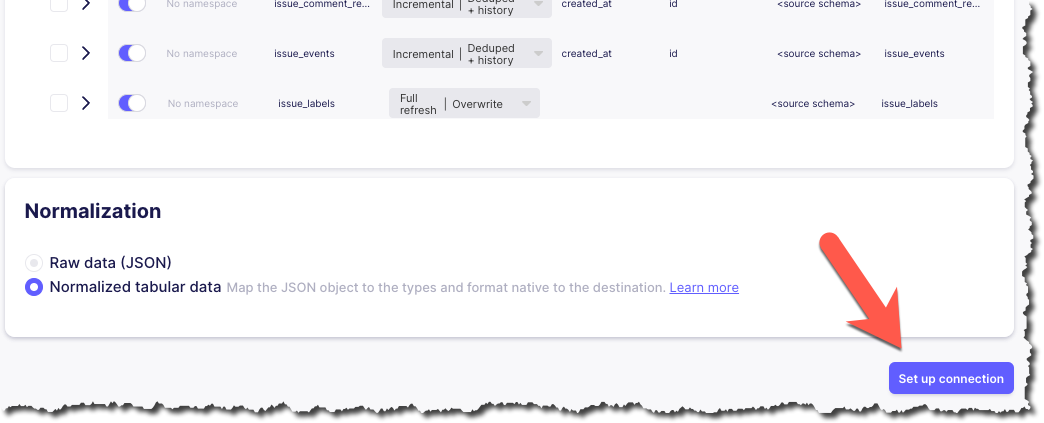
-
Second, assuming I want to change the stream sync config, this UI is even more confusing. I click on one or more checkboxes next to a stream, and something appears at the top? Why does Sync toggle but not change the toggles below? And is
Applygoing toApplyall the connector changes or just the streams that are checked? These are rhetorical questions and I can probably guess - but I shouldn’t have to.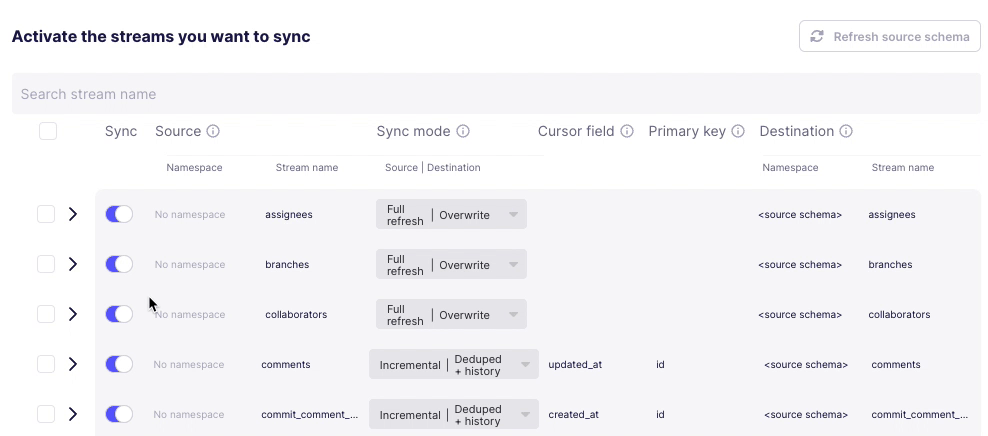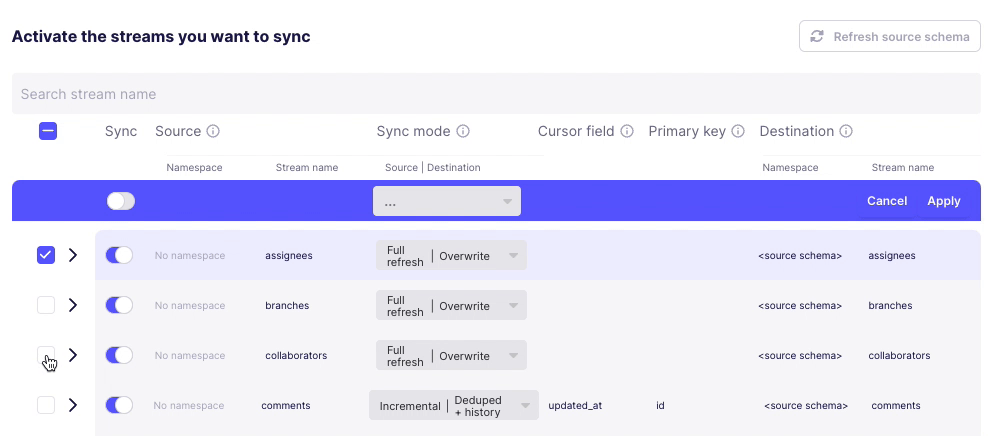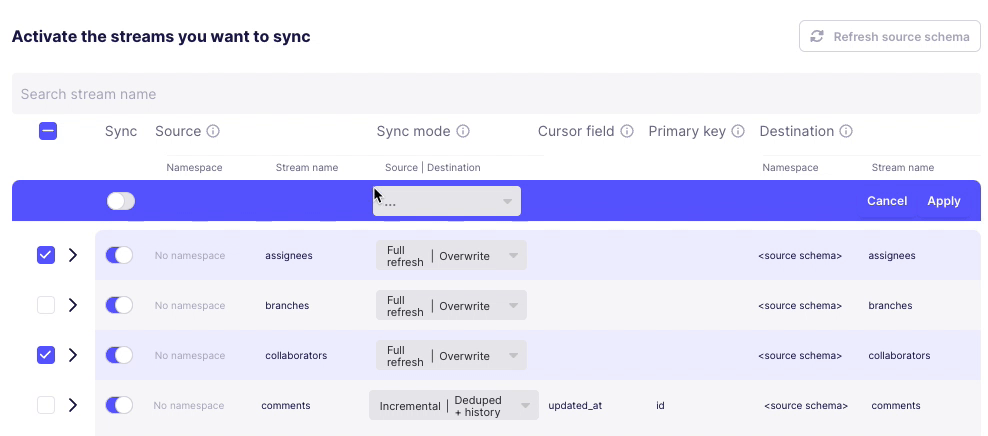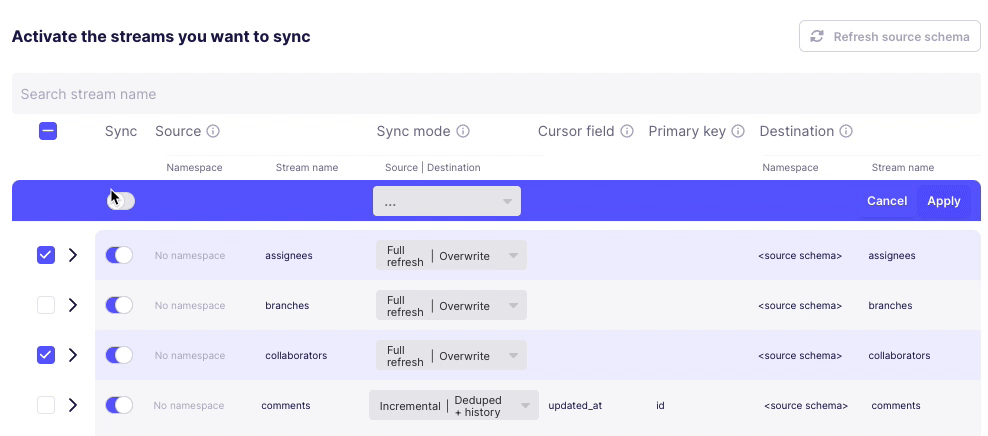
-
Perhaps GitHub is an unfortunate source to have started with, because the list of objects to sync is so long. For now, I ignore all the scary stuff and just click on Set up connection. Now I’m back to the nice-and-easy workflow, and the synchronization has started

Back in Fivetran world I’ve still not received the promised email so I head to Setup and Edit connection details to see if I can tell it to forget the bit about masking fields (because I just want to set up a pipeline, any pipeline) and just start synchronising.
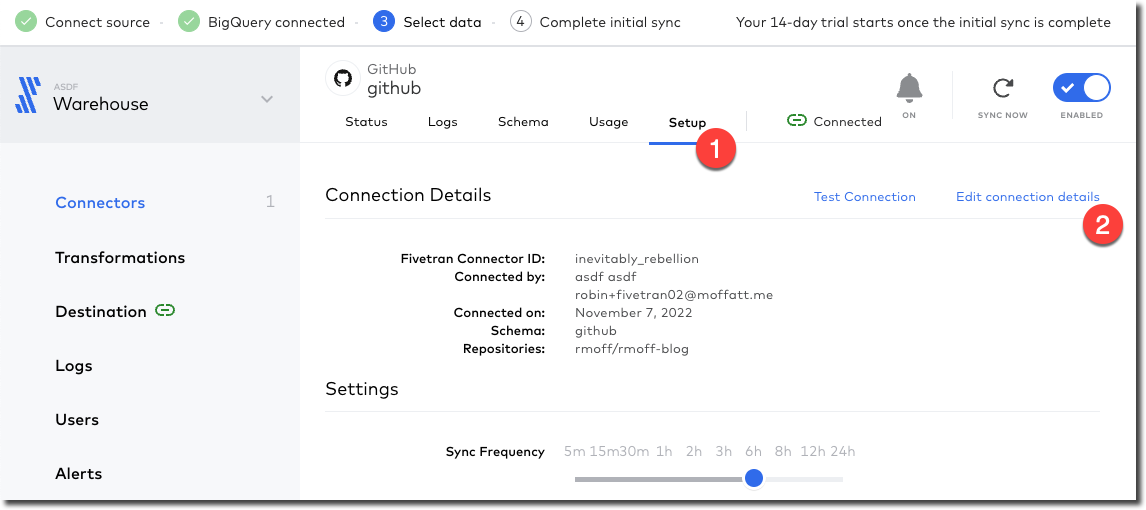
Strangely it’s not under Setup (but I only find this out after waiting for it to test the connection again), but Schema. Which kinda makes sense, except the wizard workflow was as one, so in my defence I expected it all under Setup 🤷
Looking at the schema, I can select which objects and fields within them to sync. If I didn’t want to include the author of a commit, for example, I could drop that here.
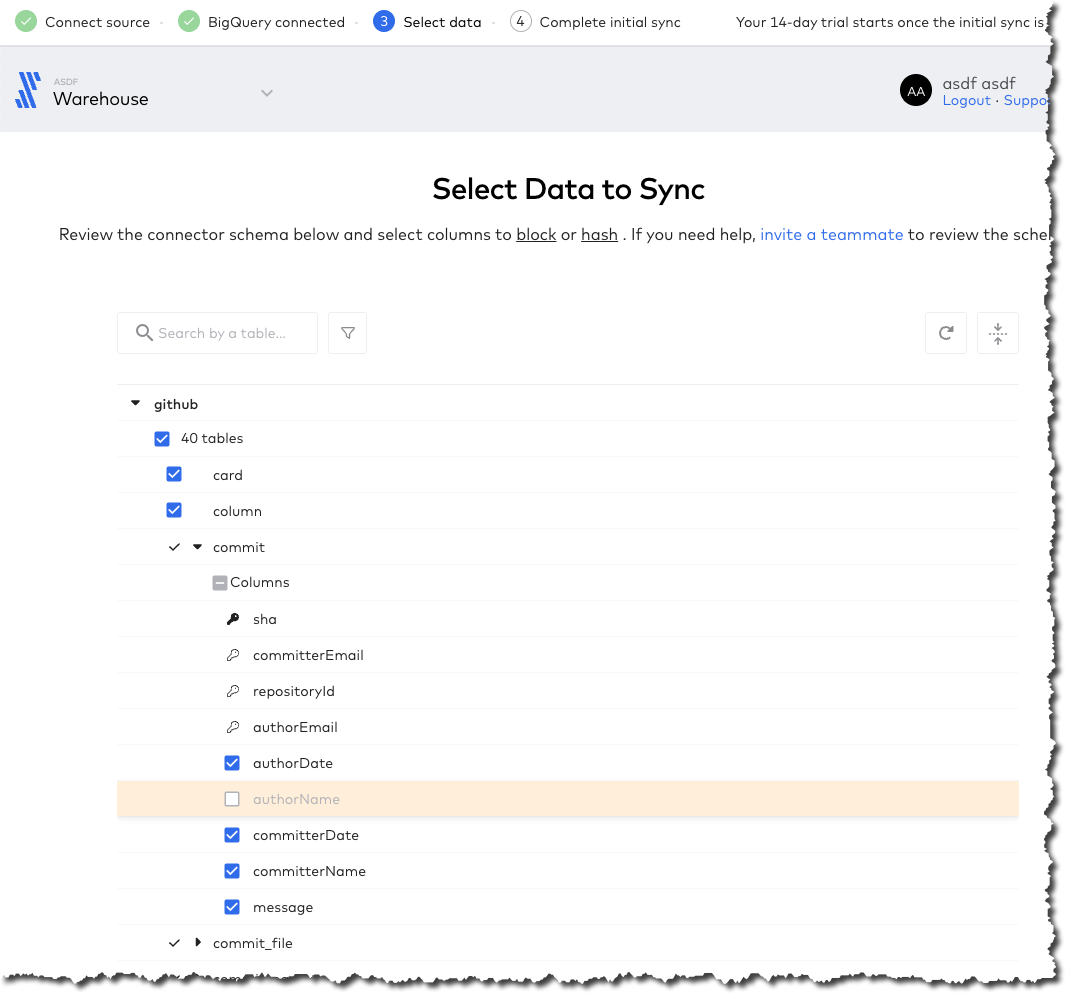
After hitting Save and Continue I get an error which is a shame
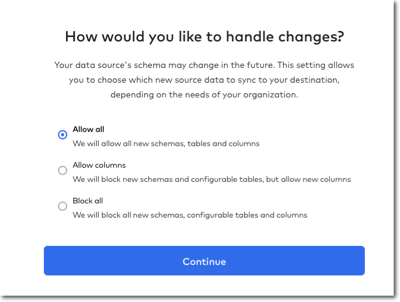
Ignoring the error I’m then prompted for how I’d like to handle schema changes, with a helpful description under each - and after that, a nice big button to click on to start the initial sync 😅
Sync status and details 🔗
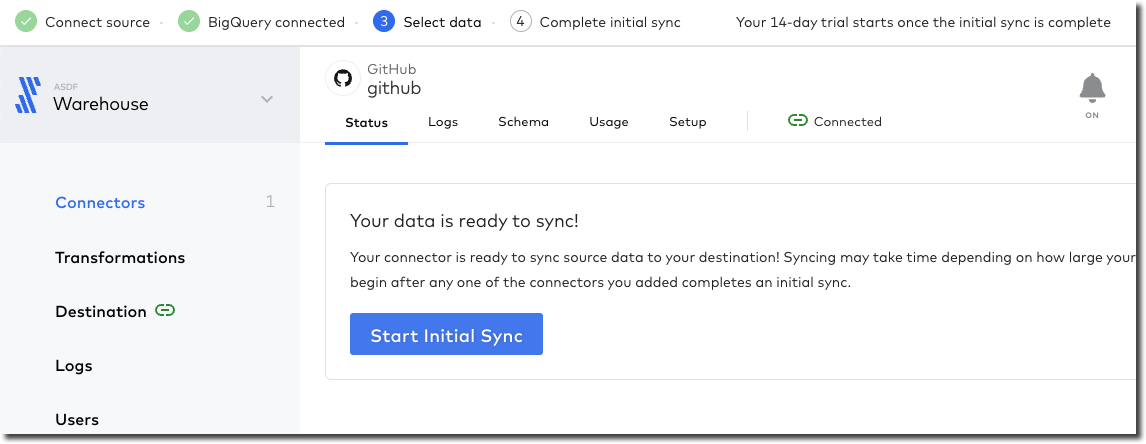
I’m now at the point at which both tools are successfully pulling data from GitHub to load into BigQuery. Each has a status screen and a view with logs and more details. If I’m being fussy (which I am) the Airbyte UI is more responsive to the window width, whilst the Fivetran one I have to keep resizing because of a left-hand nav which seems intent on grabbing a fair proportion of the available space for not much purpose…
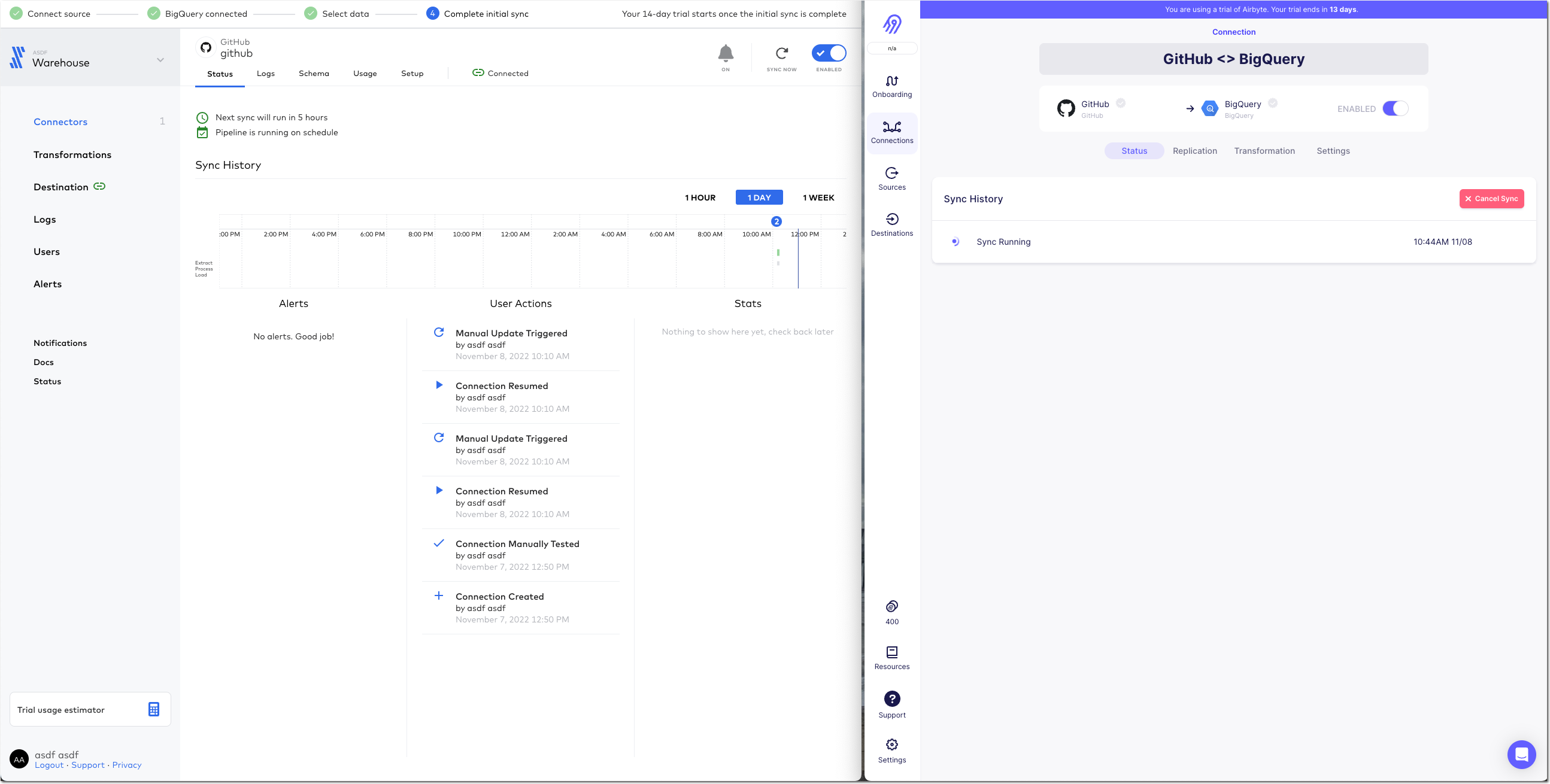
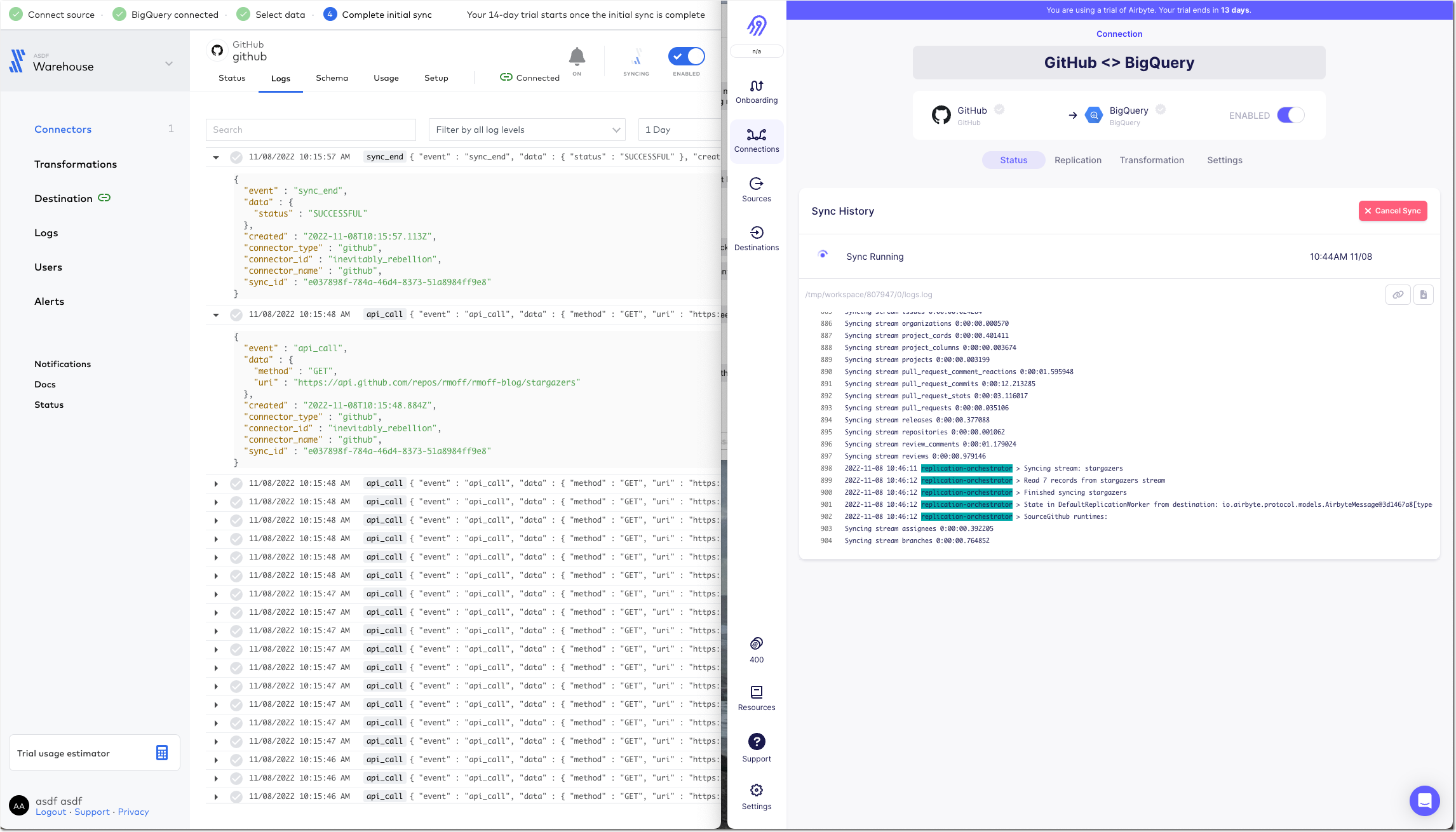
The two connectors are either pulling different data or implemented differently because whilst the Fivetran connector finishes within a few minutes, the Airbyte one is still going after more than 20 minutes and shows that it’s also been rate-limited and so paused itself for a further ~40 minutes
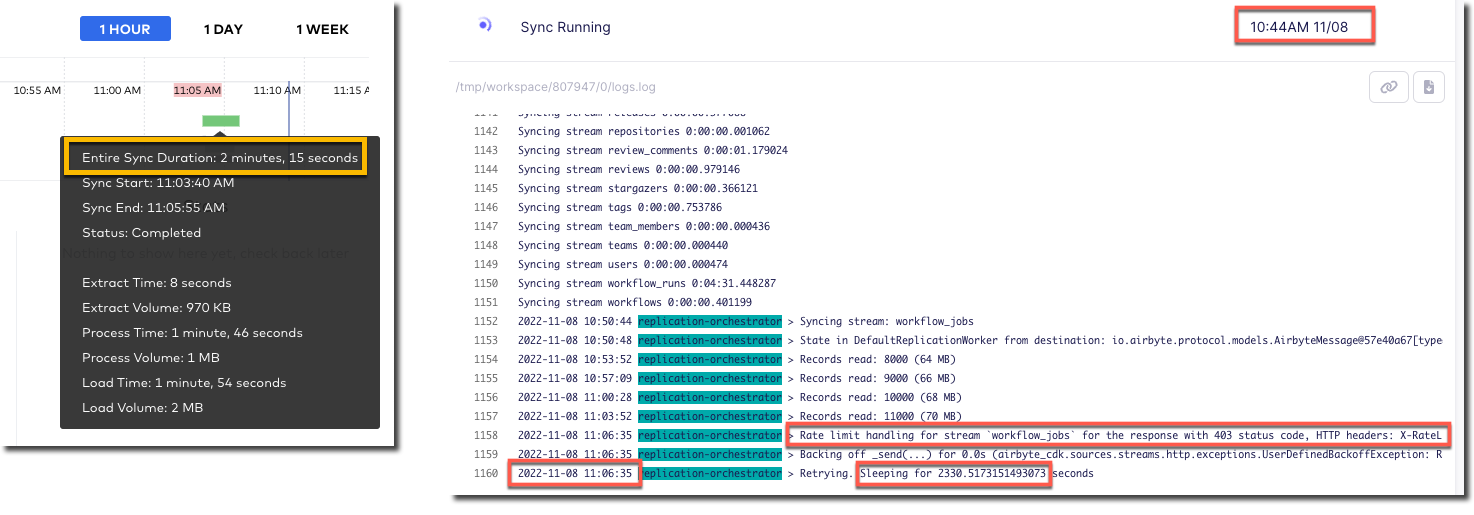
Airbyte eventually completed after over an hour - but also with 72MB of data vs 2MB from Fivetran.
The data models in BigQuery 🔗
Fivetran and Airbyte load the data from the GitHub API into quite different tables in the destination. Whilst Fivetran uses a separate staging dataset Airbyte uses a whole bunch of underscore-prefixed tables within the same target dataset as the resulting tables.
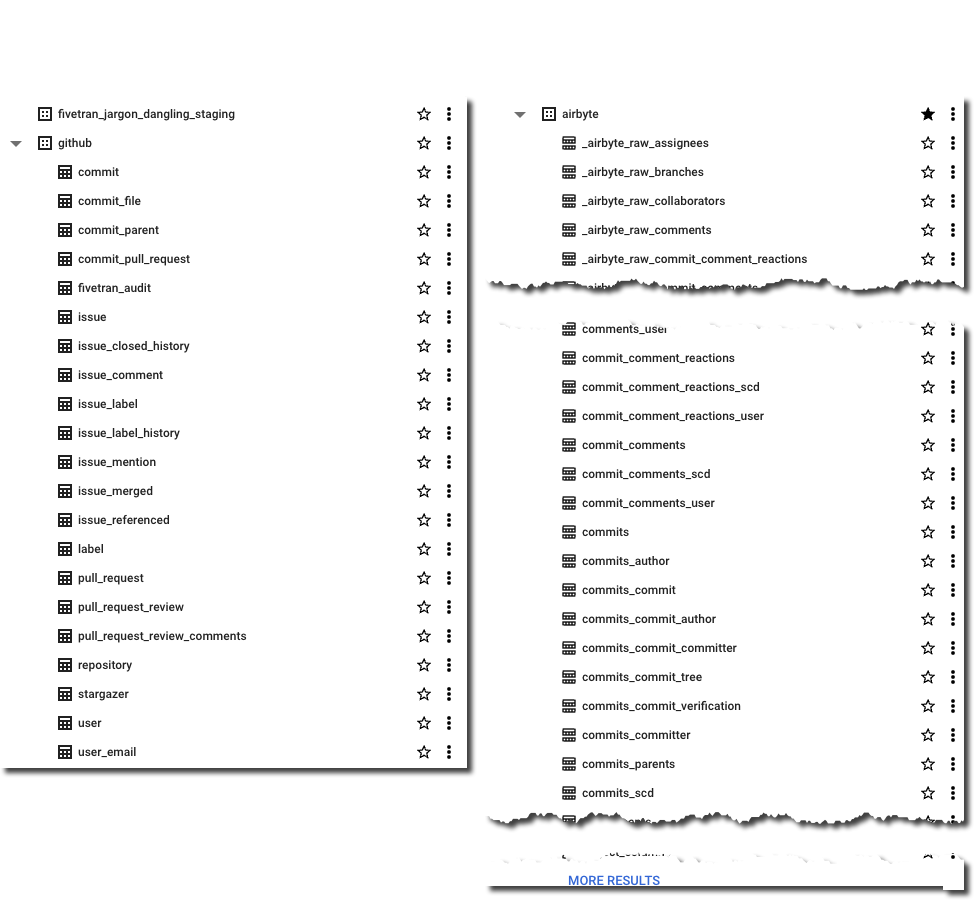
Fivetran have published an Entity Relationship Diagram (ERD) for their GitHub model (proving that data modelling never died and is actually remarkably useful) as well as general documentation about how the connector handles deletes etc. It also ships a dbt model of this ingested data as well as enrichment transformations for dbt for the data in this format.
Airbyte’s documentation and model palls in comparison to Fivetran’s. Their docs cover the connector’s characteristics but nothing about the model itself. From what I can tell in the docs the objects written to BigQuery are basically a literal representation of what the GitHub API returns (and these are what are linked to in the docs, such as the commits object). As we’ll see in the next section, this makes the data much harder to work with.
Analysing the data 🔗
Going back to the idea of this exercise, I’ve got GitHub data so now I’ll try and analyse it. The Fivetran model is easy to work with, and just needs a single join out to another table which is easily identified to pull in the repository name and show a list of individual commits by author:
SELECT author_date,
author_name,
message,
name AS repo_name
FROM `devx-testing.github.commit` c
LEFT JOIN `devx-testing.github.repository` r
ON c.repository_id = r.id
ORDER BY author_date DESC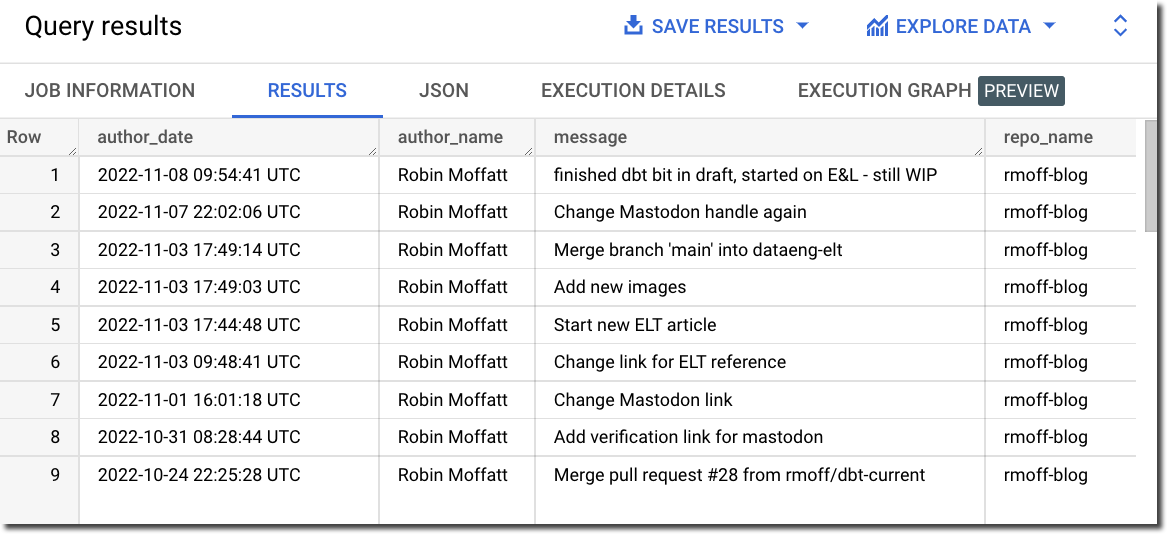
I can also aggregate based on DATE(author_date) and author and dump the resulting dataset into Data Studio/Looker to produce some nice charts:
SELECT DATE (author_date) AS commit_date,
author_name,
COUNT(*) AS commit_count
FROM `devx-testing.github.commit` c
GROUP BY commit_date,
author_name
ORDER BY 1 ASC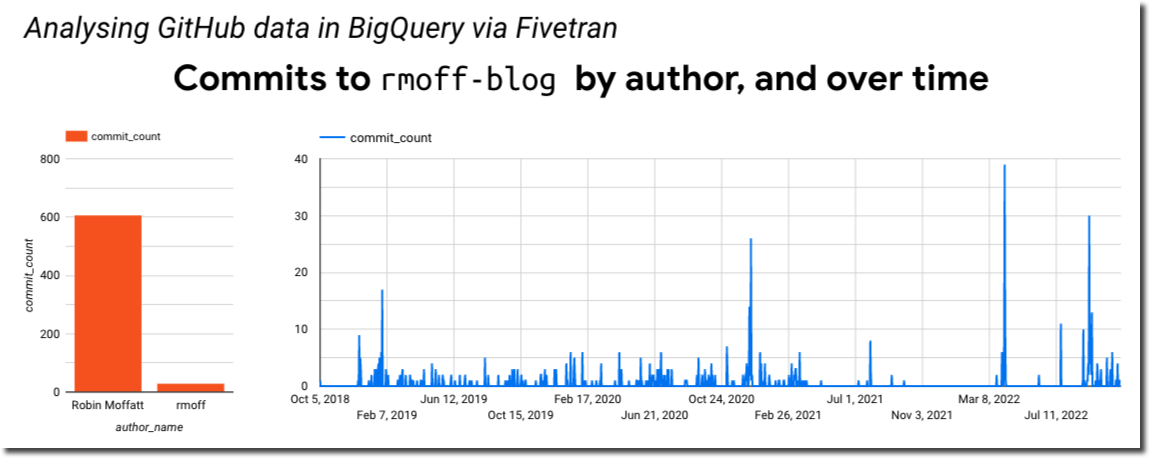
Let’s take a look at the Airbyte data. There are 16 commit-prefixed tables. If we start with the obvious commits neither the schema nor preview immediately calls out where to start.
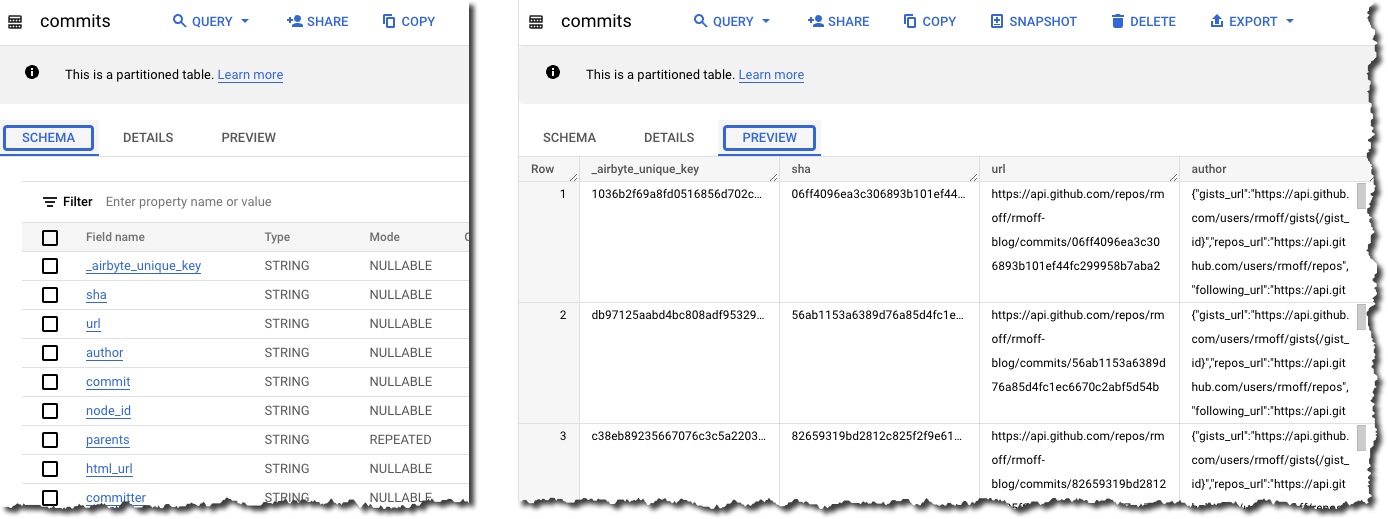
We need the date of commit, the name of the committer, the commit message, and the name of the repo. After poking around commits_commit looks useful and gets us part-way there:
SELECT JSON_EXTRACT (author, "$.date") AS author_date,
JSON_EXTRACT (author, "$.name") AS author_name,
message
FROM `devx-testing.airbyte.commits_commit`
ORDER BY author_date DESC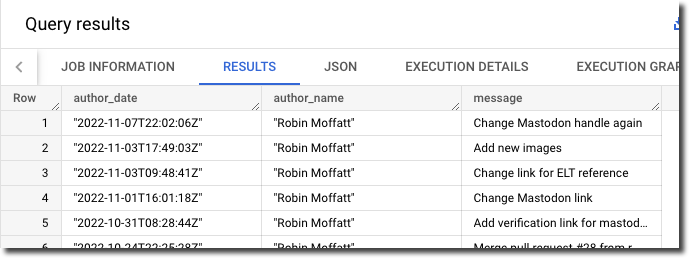
But we’re missing the repository name. Now since we specified in the Airbyte extract to only pull data for the rmoff-blog repo then we could brush this under the carpet. Otherwise we need to work out how to relate commits_commit to other tables and find one with the repo name in too…which for now I’m going to punt into the TODO realm :D
Fivetran and Airbyte - Summary 🔗
Both tools work well for easily ingesting data from GitHub into BigQuery. My assumption is that the experience is similar for all of the other sources and destinations that they support. Select the connector, configure it, and hit the big "Start Sync" button. Some connectors especially in the RDBMS world are probably going to be more fiddly to configure. Of the two tools, Fivetran definitely leans more nicely into the approach of using sensible defaults and only insisting on user input where necessary when compared to Airbyte.
Each have their own UI quirks, especially Airbyte’s "Stream activation" section that I grumbled about above.
The resulting data is more nicely modelled by Fivetran whereas Airbyte just gives you the raw API output (from what I can tell). The ERD that Fivetran publishes is a very nice touch, as are the dbt data models since it’s a fair assumption folk will be interested in using these to speed up the "time to delivery" further.
I had the privilege of ignoring one of the big real-world evaluation criteria for tool selection: cost. Both tools had a 14-day free trial, and selective browsing on Reddit suggests that the costs can quickly mount up with these tools (as with many SaaS offerings) if not used carefully.
Going off on a tangent - Bespoke API Ingest 🔗
Something that I’d not spotted yet on my travels was a canonical pattern for ingesting data from a bespoke [REST] API. All the SaaS E/L tools have the usual list of cloud-and-on-premises data sources, but there are innumerable other sources of data that expose an API. This could be an in-house system for which the backend database isn’t made available (and the API provided as the only interface from which to fetch data), or it could be a third-party system that only offers a API.
Some examples of public third-party APIs would be the kind of data sources I’ve used for projects in the past, including flood monitoring data from a REST API, or the position of ships near Norway using an AIS endpoint.
I asked this question on r/dataengineering and LinkedIn and got a good set of replies, which I’ll summarise here. One of the things that I learnt from this is that there’s not a single answer or pattern here—it’s definitely much more of an area in which you’ll have to roll up your sleeves, whether to write some code or evaluate a bunch of tools with no clear leader in the field. A lot of the solutions drop back into either writing some code, and/or self-managing something. I thought there might be an obvious Fivetran equivalent, but it doesn’t seem so.
-
Go write some code and run it with an orchestrator
-
Apache Airflow, and the HttpOperator
-
-
The Stitch Data / Singer.io ‘import api’ - "It’s sort of a best-kept secret of the platform and can be used for arbitrary data" (thanks
fraseron dbt Slack for suggesting this)
-
-
-
No/low-code
-
Portable.io — Gold star ⭐️ to
ethan-aaronwho actually filmed a video example of this in action in response to my question
-
I definitely want to try out some of these - perhaps the Airbyte one since that’s what I’ve already been using here. Stay tuned for another instalment :)
Data Engineering in 2022 🔗
Check out my other articles in this series of explorations of the world of data engineering in 2022.
